
Reproduce GPT-2 124M复盘
- 视频:Let’s reproduce GPT-2 (124M)
- 参考代码仓库:building-from-scratch
- colab复现:colab code training
- 详细日志:wandb
- 最终结果:val-loss:2.99,hellaswag-acc:31.71%
| val-loss | helloswag-acc |
|---|---|
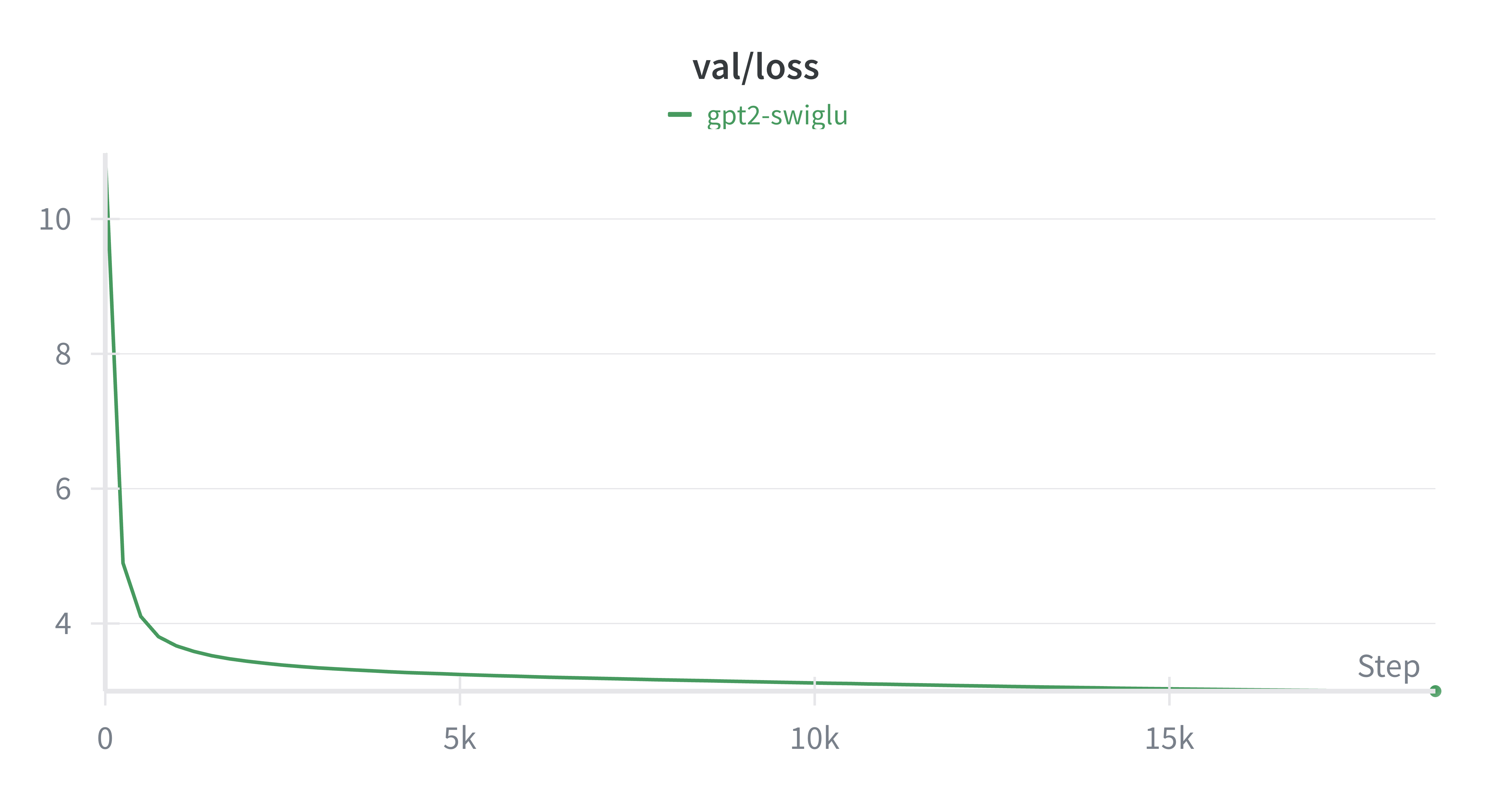 |
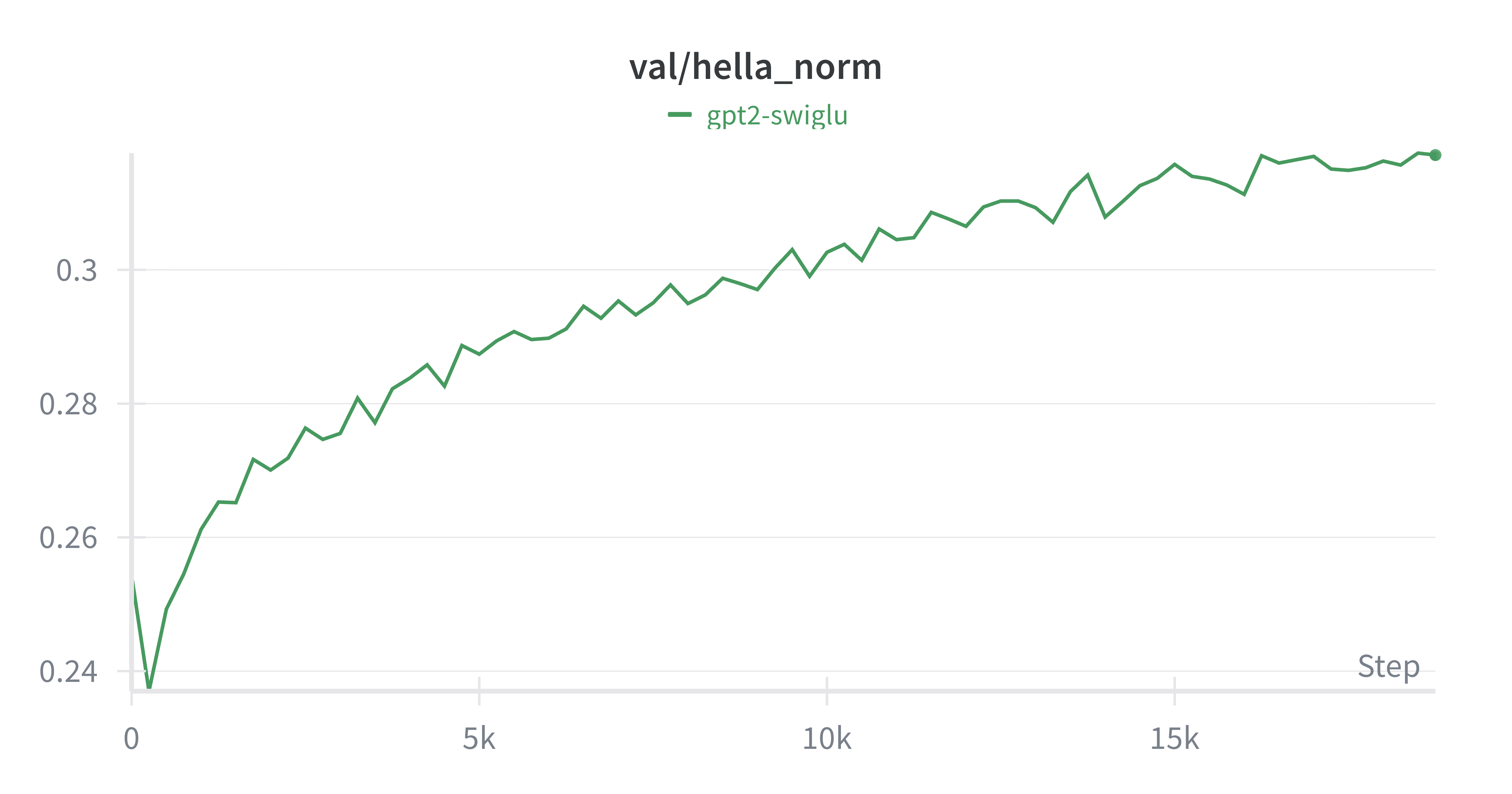 |
基本配置
- 模型:GPT-2 124M,即small款
- 数据:ShallowU/FineWeb-Edu-10B-Tokens-NPY
- 显卡:colab 一张H100,80G Mem
- 训练时间:7h左右
- 训练token/s:43万多token/s
模型架构
训练超参数设置:
# -------------------------------------------------------------#
# params
# -------------------------------------------------------------#
wandb_project = "pre-training" # wandb project name
wandb_run_name = "gpt2-swiglu" # wandb run name
data_root = "/workspace/shards" # data root
ckpt_dir = "/workspace/ckpt" # checkpoint directory
eval_interval = 250 # (steps) interval for validation and hellaSwag evaluation
log_interval = 1 # (steps) interval for logging
grad_norm_clip = 1.0 # global norm gradient clipping
# data
total_batch = 524288 # 2^19, ~0.5M tokens, matching GPT-3 124M model
B = 64 # batch size
T = 1024 # sequence length
# optimizer hyperparameters
max_lr = 1.5e-3 # maximum learning rate
min_lr = max_lr * 0.1 # minimum learning rate
warmup_steps = 300 # number of warmup steps, this is from original GPT-3 paper, and is too conservative, we can even go with like 100 steps
max_steps = 19073 # total number of steps, FineWeb-Edu 10B tokens (1 epoch training 10B/ 2^19)
weight_decay = 0.1 # weight decay for optimizer
betas = (0.9, 0.95) # betas for optimizer
# model
vocab_size = 50304 # vocabulary size 50,000 merges + 256 byte pieces + 1 <endoftext> token -> nice number: 50,304
n_layer = 12 # number of layers
n_embd = 768 # embedding dimension
n_head = 12 # number of attention heads
# system
device = "cuda" # device to use, "cuda" or "mps" or "cpu" (DDP only for "cuda")
seed = 42 # seed for the random number generator
data_seed = 1337 # seed for the data shuffle
use_compile = True # use torch.compile to further speedup the model
# eval
val_loss_steps = 20 # number of steps for validation loss
num_return_sequences = 4 # number of return sequences
max_seq_len = 32 # maximum sequence length
start_seq = "Hello, I'm a language model," # start sequence
run_validation = True # flag for running validation
run_hellaswag = True # flag for running hellaswag
run_gen_samples = False # flag for running generation samples
模型架构,transformer架构,在位置编码、norm、ffn上可以改变替换:
class GPT(nn.Module):
def __init__(self, config:GPTconfig):
super().__init__()
self.config=config
self.transformer=nn.ModuleDict(
dict(
wte=nn.Embedding(config.vocab_size,config.n_embd),
h=nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f=nn.RMSNorm(config.n_embd),
)
)
self.lm_head=nn.Linear(config.n_embd,config.vocab_size)
self.transformer.wte.weight=self.lm_head.weight # 权重共享
self.apply(self._init_weights)
性能加速
- ddp分布式数据并行的使用
model.require_backward_grad_sync = (micro_step == grad_accum_steps - 1)
dist.all_reduce(loss_accum, op=dist.ReduceOp.AVG)
- Flashattention的使用
self.transformer.wte.weight = self.lm_head.weigh,权值共享减少了30%的参- torch compile的使用
torch.set_float32_matmul_precision("high"),TF32乘法加速- 混合精度
with torch.autocast(device_type=device_type, dtype=torch.bfloat16)加速
优化训练
-
RoPE的工业实现中,使用了rotate_half模拟,最后
x * cos + rotate_half(x) * sin -
使用RoPE、SwiGLU、RMSnorm公认优秀架构替代最初GPT-2
-
模型初始化参数中,避免残差连接导致的前向传播激活值方差变大和爆炸,需要1/sqrt(2*n_layer),即attn层和ffn层的proj进行缩放
def _init_weights(self, module): # 0.02 is roughly in range of Xavier initialization. As Xavier initialization is 1/sqrt(n_in), so for n_in = [768-1600], the std is ~ 0.02 if isinstance(module, nn.Linear): std = 0.02 if hasattr(module, "NANOGPT_SCALE_INIT"): # according to GPT-2 paper, we need to scale down the weights by 1/sqrt(2*n_layer) to control the growth of activations inside the residual stream in the forward pass std = std * (1 / math.sqrt(2 * self.config.n_layer)) torch.nn.init.normal_(module.weight, mean=0.0, std=std) if module.bias is not None: torch.nn.init.zeros_(module.bias) elif isinstance(module, nn.Embedding): torch.nn.init.normal_(module.weight, mean=0.0, std=0.02) -
优化器使用fused加速,并且权值衰减
-
训练的DataLoader重写,将所有的索引窗口进行打乱,训练数据更随机,loss下降更低
-
学习率使用带预热的余弦调度衰减
-
torch.nn.utils.clip_grad_norm_(model.parameters(), grad_norm_clip)梯度裁剪和梯度累积使用 -
学习率较andrej karpathy的提高了3x,为1.5e-3
语法技巧
- dataclass的装饰器使用,更方便配置模型的config
- wandb日志的记录非常方便
@torch.no_grad()推理不构建反向传播,model.eval()/train 的切换,val_loss_accum += loss.detach()切断计算图
为什么结果更好?
- 1.FineWebEdu数据集质量更好,虽然只有10B token
- 2.采用了更新型的RoPE、SwiGLU、RMSnorm公认优秀架构
- 3.shuffle全局数据的load方式更友好
- 4.带预热的余弦调度衰减、梯度裁剪、优化器权值衰减、参数初始化技巧
遇到的问题
1.loss损失曲线毛刺很多,来回的波动震荡
描述:在训练初期,我观察到 Loss 曲线存在严重的低频震荡现象。经过排查,发现这是由于数据分布的非独立同分布(Non-I.I.D.)导致的。原始数据加载方式是按 Shard 顺序读取,同一 Shard 内的文本往往属于同一领域(如全是数学教材或全是小说),导致模型在切换 Shard 时发生灾难性遗忘(Catastrophic Forgetting)或剧烈适应。
解决:由于数据集的加载是连续按顺序的,按一个个shard的连续顺序。有些分片内容容易学习,loss下降。而有些学习困难,loss反而震荡上升。重写dataloader,随机打乱每个分片内文档的顺序。先打乱整个shards顺序,最后再打乱每个小的batch的index采集,即最后呈现的是 indices to (shard, position) tuples格式。
重构了 DataLoader,实现了全局级别的动态 Shuffle。具体来说,我先构建了所有 Shards 中 Window 的全局索引,然后对索引进行随机打乱。为了平衡 I/O 性能,我利用了 numpy.memmap 配合 OS 的 Page Cache,既保证了数据的随机性(Decorrelation),又避免了频繁随机读盘导致的吞吐量下降。最终 Loss 曲线变得平滑,收敛速度明显加快
2.刚开始训练直接loss爆炸然后Nan
描述:在模型层数加深时,我遇到了训练早期的梯度爆炸问题,导致 Loss 直接变为 NaN。这是深层 Transformer 的典型问题。在残差结构 $x_{l+1} = x_l + F(x_l)$ 中,随着层数 $L$ 的增加,残差流(Residual Stream)的方差会线性累积,导致输出层附近的激活值幅度过大,反向传播时梯度不稳定。
解决:参数初始化时候,最重要就是在每个block里的投影层进行缩放,标准差使用math.sqrt(2 * self.config.n_layer)缩放,这样会抵消由于残差连接汇聚一次次的方差爆炸震荡,网络越深就越容易造成震荡导致爆炸。
我采用了 GPT-2 论文中的初始化策略(也是 Megatron-LM 的标准做法),对每个残差分支(Residual Branch)的输出权重(即 MLP 和 Attention 的 c_proj 层)进行缩放,缩放系数为 $1/\sqrt{2L}$。这有效地控制了信号在深层网络中的方差增长,使得模型在使用了 Pre-Norm 的结构下也能稳定启动训练
3.优化训练的token/s速度?(在batch 架构等参数大致固定情况下
1.参数是2的幂次方,方便GPU计算,vocab size从50257调整至50304
2.torch compile的使用
3.Flashattention2的使用加速attention计算
4.混户精度训练,以及设置torch.set_float32_matmul_precision(“high”) 矩阵tf32计算
为了在有限算力下极致压榨 GPU 性能,我从计算密集型和访存密集型两个角度进行了优化,最终将 MFU(模型算力利用率)提升到了较高水平:
访存优化 (Memory Bound):引入 FlashAttention-2,通过 Tiling 技术在 SRAM 中完成 Attention 计算,大幅减少了 HBM(显存)的读写次数,这是提升 Transformer 速度的最关键一步。同时将词表大小 Padding 到 50304(64的倍数),满足 GPU 内存对齐要求。
计算优化 (Compute Bound):开启 TF32 和 BF16 混合精度训练,充分利用 Ampere 架构 GPU 的 Tensor Cores 进行矩阵乘法加速。
编译优化 (Compiler):使用 torch.compile 进行图编译,它能自动进行算子融合(Kernel Fusion),减少了 Python 解释器开销和 CUDA Kernel 启动的 Overhead。”
4.OOM (Out Of Memory) 与 显存管理
问题场景:虽然模型只有 124M,但 Batch Size 开大或者 Context Window 变长时,显存依然不够。
回答建议:
“在尝试增大 Batch Size 以稳定梯度估计时,我遇到了 OOM 问题。我没有简单地减小 Batch Size(这会影响收敛),而是实现了梯度累积(Gradient Accumulation)。 我将一个大 Batch 拆分为多个 Micro-Steps 串行计算,只在最后一步进行 optimizer.step()。这里有一个细节坑:在 DDP 模式下,如果不处理好,每次 Micro-Step 都会触发梯度同步(AllReduce),极大地拖慢速度。我通过设置 model.require_backward_grad_sync = False,只在最后一个 Micro-Step 同步梯度,既解决了显存问题,又保证了多卡训练的效率。